
























Block Specimen Producer
Interested in the build specification? Check out the Github Repo
Essential to the Covalent Network is the Block Specimen and the Block Specimen Producer (BSP), a bulk export method that ultimately leads to the generation of a canonical representation of a blockchains historical state. Currently implemented on existing blockchain clients running Geth. It functions currently as an:
-
- Blockchain data extractor
-
- Blockchain data normalizer
What is ultimately created is a ‘Block Specimen’, a universal canonical representation of a blockchains historical state.
There are two further considerations regarding the Block Specimen.
-
- The BSP is completely standalone on forks of Geth.
-
- The separation of data storage layer from the block execution and distributed consensus functionality leads to better segregation and upgrades of functionality in the blockhain data processing pipeline.
As a result, anyone can run full tracing on the block specimen and accurately recreate the blockchain without access to a blockchain client software.
Get Started as a Block Specimen Producer
Hardware Requirements
The recommended configurations will make sure the sync is not lag prone and the node is able to keep up with the Ethereum network.
Minimum requirements
- CPU with 2+ cores
- 4GB RAM
- 320GB free storage space to sync the Mainnet
- 8 MBit/sec download Internet service
Recommended
- Fast CPU (eg:-Intel Core i7-4770) with 4+ cores
-
= 32 GB+ RAM
- Fast SSD with >= 500GB storage space
- 25+ MBit/sec download Internet service
Software Requirements
Install the given versions of the following software
- 64-bit Linux, Mac OS
- SSL certificates
- Git
- BSP v1.1.5 ships with geth Version: 1.10.17 stable
- Go v1.16.4
- Redis v7, Redis-cli 6.2.5
- Listener TCP and UDP discovery port 30303
- ICMP IPv4 should not be closed by an external firewall
Architecture Overview
A lot happens from the client node to the block-specimen production-proof transaction being uploaded to the Covalent virtual chain. Let’s break down each step, assuming that the validator is using go-ethereum as the underlying EVM-based blockchain node that houses the BSP modifications.
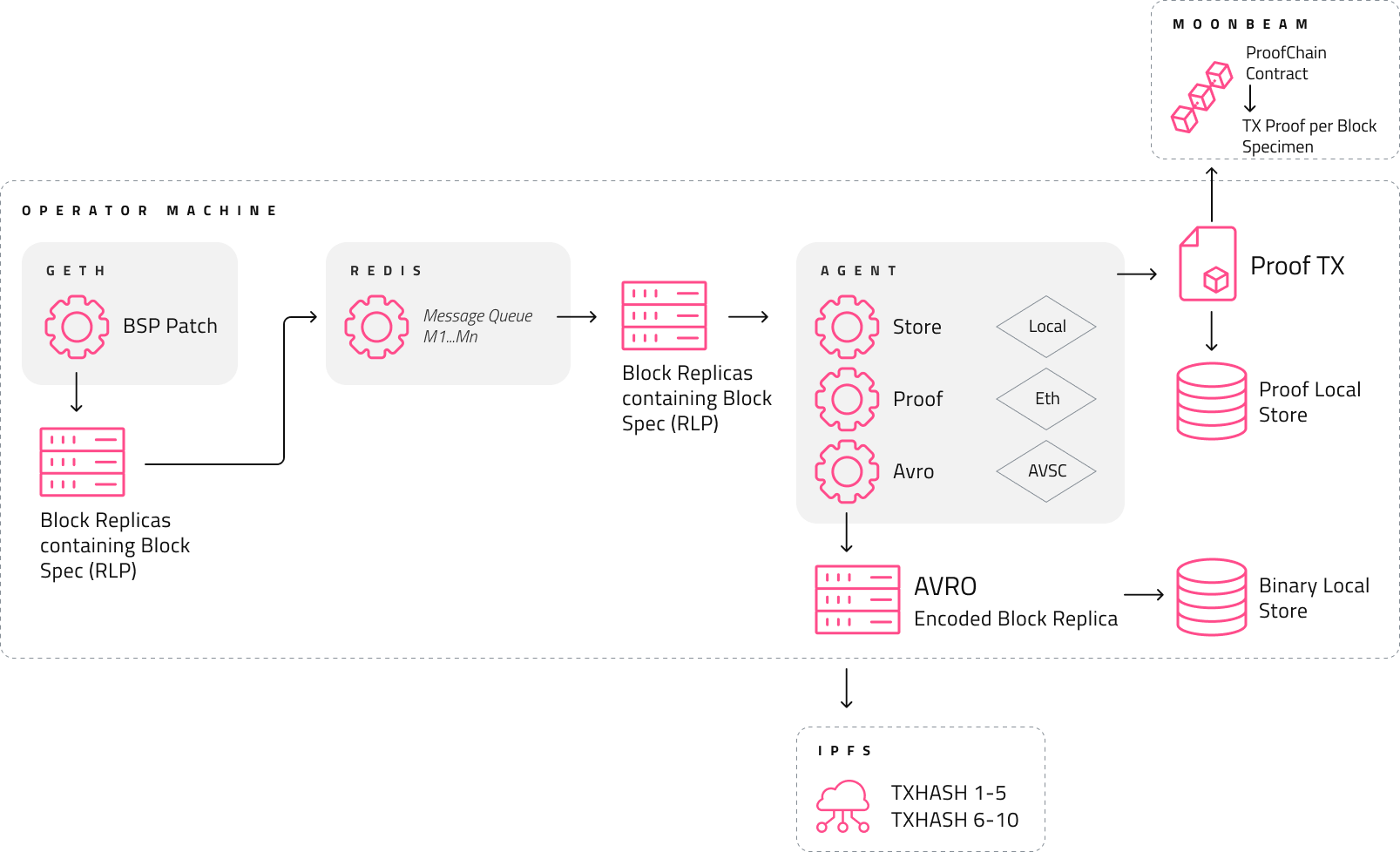
Once go-ethereum is run with the correct configurations, Block Specimens are created as the node catches up historically from block 0 or even if it just starts syncing from the block number where it left last off after the Geth process was stopped (with or without the patch). The operators have the ability to decide from which block they would like to start producing specimens.
Once the producer is correctly started, Block Specimens are created for every block that is executed and consequently synced with Geth. These specimens are then sent off to a Redis streaming service (that the validators need to run on the same system as the Geth process) at the particular topic key where the Agent can listen for receiving these messages.
Within the Agent, this topic key can be set along with a number of other configurations. These include how to pack incoming streamed messages so that they can be stored in any storage device. The “how” refers to the given size (contents), encoding used (AVRO), and location (GCP, AWS, or IPFS for example) of the block specimens for storage.
As each message is streamed to the Agent, the Agent firstly makes sure that the message follows the format it expects to receive from a BSP. If for example, it receives messages from another topic that does not conform to the expected schema, the application stops any further processing. Secondly, once the messages are verified to be in the correct format matching the Block Specimen schema, it proceeds to pack multiple stream messages into an array of block specimens within a single binary encoding using AVRO (a .avsc schema). The size of packing is specified at the initialization of the Agent.
The AVRO encoding for packing multiple Block Specimens is basically the process of segmenting the messages into batches and processing them for proving and storing them in those exact batches. Thirdly, the Agent keeps track of every stream message that’s been verified and segmented into a batch and then encodes (compressing) them using this codec converting them into a single binary array of multiple specimens. Finally, after evaluating an entire segment the Agent has the capability to talk to a proof-chain contract deployed on the earlier specified blockchain node. It takes the binary specimen object that’s ready for storage, does a SHA256 sum over its contents, and calls a payable function on the BSP-Proof-chain contract that is pre-deployed to the corresponding node that it is talking to.
The Agent effectively makes a provable (or dis-provable) commit regarding the work it’s done so far on the Block Specimen segment object itself. Once this proof-of-creation transaction is mined, the Agent proceeds to upload the object it’s already made the commit for to the specified object storage service location provided in the initialization configuration.
Between reading each stream message and storing a Block Specimen object representing an evaluation (validating and proving) process, the Agent performs a bunch of processing expensive operations including a single gas expending operation of writing the proof-of-creation of Block Specimens to an(y) EVM based blockchain. The chain that the agent writes to is also specified during the initialization of the Agent.
The process of evaluating a message, segmenting multiple messages into a single AVRO encoding, making a statement regarding the work done by making a transaction on-chain, and finally uploading the segment is an entirely atomic process. All of the above will either go through or none of them will. Anyone section failing in this chain at any point leads to the failure of the entire process within the Agent. In case of such failure, the exact reason is made as explicit as possible in the logs from where corrections can be applied during initialization. The messages in the Redis stream are persisted in the queue, in case a failure in the processing chain happens thereby making sure that if at all - only fully evaluated, encoded, and proved (processed) segments get uploaded to any storage service.